【百萬小學堂】、【金頭腦】這類的益智節目,在台灣也風靡一時。
而電腦是否能在節目上超越人腦,也一直是人們茶餘飯後討論的話題。
在 2011 年的益智問答節目 Jeopardy中,IBM 的華生電腦(Watson)擊敗兩位世界紀錄保持人並贏得 100 萬美元,造成不小轟動。本次talk,將介紹如何自製一個答題機器人。
目前,電腦對於自然語言的理解依然有限,舉例來說:要讓電腦知道『蘋果』是什麼?就是個困難的問題。
因為蘋果在一句話中可能是指水果、手機或是喜歡的人(流行音樂中的小蘋果)。為了克服這個難題,文字探勘(text mining)中有個子領域叫做知識圖譜(Ontoloty),目的就是希望將人類所有的知識以及規則儲存成結構化的資料。
如此,在解析文字時,就會知道蘋果是水果or電腦、知道周杰倫是歌手。對益智節目、聊天機器人等應用都會產生莫大的助益。
本talk將會介紹知識圖譜的應用、目前的做法與瓶頸、如何使用Wikipedia自動建立支援各國語言的知識圖譜,最後Demo一下答題機器人的智商到底行不行。
# 文字探勘的應用
-------------------------------
過去大家最熟悉的,是像臉書那樣 蒐集使用者平常看得、點擊的文字等資訊
去推論使用者意圖 (User Intension)
用於推薦廣告或其他服務來增加黏著度去獲利
而近年來因為deep learning的突破,`智能助理`變成當紅的議題
機器人能當秘書、看病、答題等等
都是當今熱門的應用
# 知識圖譜
-------------------------------
什麼是知識圖譜呢?
就是用結構化的資料
來儲存下面的關係圖
1. 例子1:
2. 例子2:
一個知識圖譜應該要包含:
1. relation 例如:周杰倫 `IS-A` 歌手
2. axiom 例如:`魚住在水裡`,這類的規則
目前最成熟的應用為`IS-A`的關係
例如:
1. 周杰倫 `IS-A` 歌手
2. PyCon `IS-A` 研討會
而要從文本中提取出`魚住在水裡`這類的規則(axiom)
就困難重重
目前都需要人工的輔助
我土炮的知識圖譜也只能做到`IS-A`關係
背後的原理是下面介紹的`Word2Vec`
# 什麼是Word2Vec
-------------------------------
> 懶人包 <https://www.jianshu.com/p/f58c08ae44a6>
以前沒辦法用向量表示文字的時候
很多就只能用字串比對去進行
造成很大的限制
google研究員`Tomas Mikolov `的演算法`Word2Vec`
能把文字轉成向量後 (他不是第一個,但是目前最好之一,以前的向量都很爛...)
很多基於向量的演算法有都能套用的文字上了
讓Text Mining這個領域有大幅度的進展
# Word2Vec的視覺效果
-------------------------------
1. 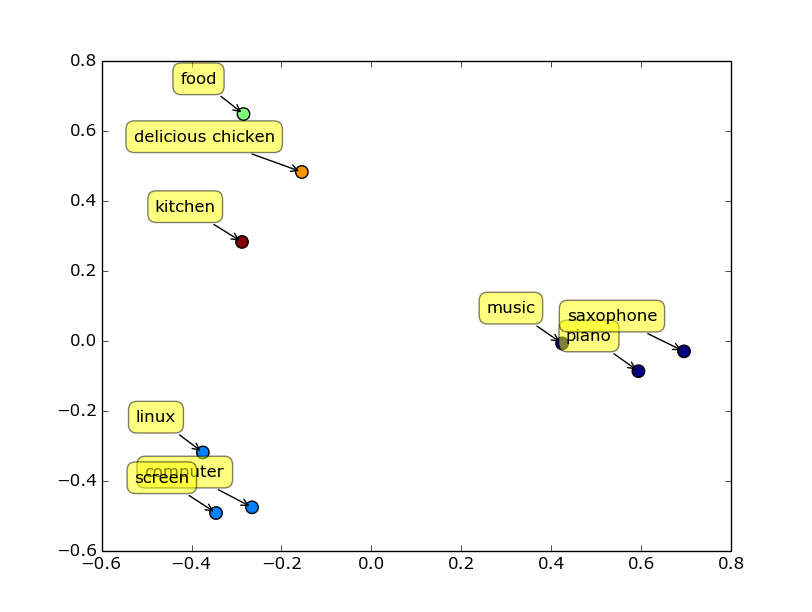
這是透過Word2Vec把文字轉成向量後
可以看到他把`電腦、linux、screen`放在向量空間的附近
效果非常準確
2. 
而這張圖透過向量減法
可以推論出`man - woman`的向量
近似於`king - queen`的向量
都是`男生到女生`的向量
